Next: Algorithm Up: Structure induction by lossless Previous: Structure induction by lossless
The explosive growth of relational data, for example data about genes, drug molecules and proteins, their functions and interactions, necessitates efficient mathematical algorithms and software tools to extract meaningful generalizations. There is a large body of literature on the subject coming from a variety of disciplines from Theoretical Computer Science to Computational Chemistry. However, one fundametal issue has so far remained unaddressed. Given a multi-level nested network of relations, such as a complex molecule, or a protein-protein interaction network, how can its structure be inferred from first principles. This paper is meant to fill this surprising gap in automated data processing.
Let us illustrate the purpose of this method through the description of DNA molecular structure, the way most of us learned it from a textbook or in class.
The properties of hierarchical description are formally well-studied and applied in other scientific domains, such as linguistics and computer science. It is viewed as the result of a rule-driven generative process, which combines a finite set of undecomposable elements--terminal symbols--into novel complex objects--non-terminal symbols, which can be combined in turn to produce the next level of description. The rules and symbols on which the process operates are determined by a grammar and the process itself is termed a grammatical derivation. In the case of the DNA molecule above, the chemical elements correspond to terminal symbols. They are assembled into non-terminal symbols, i.e. compounds, according to some set of production rules defined by chemical properties.
Now, imagine receiving an alternative description of the same object, stripped off of any domain knowledge and context, simply as an enormous list of objects and binary relations on objects, corresponding to thousands of atoms and covalent bonds. Such a list would remain completely incomprehensible to a human mind, along with any repetitive hierarchical structure present in it. Discovering a hierarchy of nested elements without any prior knowledge of a kind, size and frequency of these constitutes a formidable challenge.
Remarkably, this is precisely the challenge which is undertaken by contemporary scientists trying to make sense of data, mounting up from small fragments, like protein interaction networks, regulatory and metabolic pathways, small molecule repositories, homology networks, etc. Our goal is to be able to approach such tasks in an automated fashion.
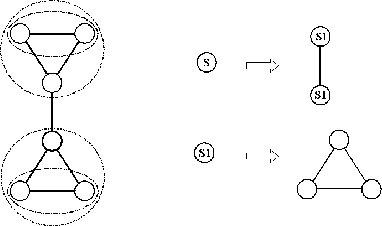
Figure 1 illustrates the kind of induction we describe in this paper on a trivial example. We will use this as a running example throughout the paper, leaving more rigorous mathematical formulation out for the purpose of clarity and wider accessibility. To the left is a graph which contains repetitive structure. Let us imagine for a moment that the human researcher is not smart enough to comprehend a 6-node graph and find an explanatory layout. Thus, we would want to automatically translate such a graph into the graph grammar on the right. The graph grammar consist of two productions. The first expands a starting representation--a degenerate graph of a single node "S"--into a graph connecting two nodes of the same type "S1". The second additionally defines a node "S1" as a fully connected triple.
Formal description of the relational data of such kind is known as graphs, while the hierarchical nested structures of such kind are described by graph grammars. It is outside the scope of this paper to survey a vast literature in the field of graph grammars; please refer to a book by G. Rozenberg [3] for extensive overview. It suffices to say that this field is mostly concerned with the transformation of the graphs, or parsing, i.e. explaining away a graph according to some known graph grammar, rather than with inducing such grammar from raw data.
The closest work related to the ideas presented here is due to D. Cook, L. Holder and their colleagues (e.g. see [2] and several follow-up papers). Their work however is not concerned with inducing a structure from given graph data. Rather, they induce a flat, context-free grammar, possibly with recursion, which is not only capable of, but is also bound to, generate objects not included in the original data. Thus, their approach defies the relation to compression exploited here. Moreover, the authors present the negative result of running their SUBDUE algorithm on just the kind of biological data we successfully use in this paper. Another remotely similar work is by Stolke [10] in application to inducing hidden Markov models. There are many other works attempting to induce structure from relational data or compress graphs, but none seem to relate closely to the method considered here.
Our method builds on the parallels between understanding and compression. Indeed, to understand some phenomenon from the raw data means to find some repetitive pattern and hierarchical structure, which in turn could be exploited to re-encode the data in a compact way. This work extends to graphs some well established approaches to grammatical inference previously applied only to strings. Two methods particularly worth mentioning in this context for grammar induction on sequences are Sequitour [6] and ADIOS [8]. We also take inspiration from a wealth of sequence compression algorithms, often unknowingly run daily by all computer users in a form of archival software like pkzip in Unix or expand for Mac OS X.
Let us briefly convey the intuition behind such algorithms, many of which are surveyed by Lehman and Shelat [1].
Although quite different in detail, all algorithms share common principles and have very similar compression ratio and computational complexity bounds.
First, one has to remember that all such compression/discovery algorithms are bound to be heuristics, since finding the best compression is related to the so-called Kolmogorov complexity and is provably hard [1]. These heuristics are in turn related to the MDL (Minimum Description Length) principle, and work in the way described by Table 1.
Extending these methods to a graph structure turns out to be non-trivial for several reasons. First, maintaining a lexicon of strings and looking up entries is quite different for graphs. Second, directly extending the greedy approach [7] fails due to inherent non-linear entity interactions in a graph.
Leonid Peshkin 2007-03-23